가상 운영 환경 디자인
Playce Kube를 이용한 Kubernetes운영 환경을 이용하여, 실제 모의 운영을 해보려고 하는데요. 고객혹은 내가 원하는 시스템의 요건을 정리해보겠습니다.
- 요건 정리
- 엔지니어, 오퍼레이터, 개발 그룹1, 개발 그룹2, DB별로 쿠버네티스의 접근 권한이 별도로 필요함
- Sample Page를 외부에 공개 할 수 있어야 한다. 이때 도메인을 사용하여 접근가능 하여야 한다.
- Sample Page는 Log In이 가능해야 하고, Log In 정보는 DB에서 확인하여 표시한다.
- 배포가 될경우 DB에 기록하고 배포 횟수가 카운트 되어야 한다.
- 1일 1회 날씨정보를 가져와서 DB에 기록하여야 한다.
- 가져온 날씨 정보는 Log In이 된 페이지에서 표시 되어야 한다.
- Kubernetes가 정상인지 확인 할 수 있는 모니터링 페이지가 있어야 한다.
- 구축된 Kubernetes는 백업과 복원이 가능해야 한다.
- 구축된 Kubernetes의 System Log를 볼 수 있어야 한다.
- 운영중인 서비스의 Application Log를 볼 수 있어야 한다.
- 배포가 된 Application은 이전단계로 원복이 가능해야 한다.
- 배포된 Application은 사용자 요청에 따라 수평 확장/감소 해야 한다.
간단히 생각해도 많은 내용이 나오네요. 물론 위의 내용중 Service Mesh나 메모리 Cach에 대한 부분 그리고 스트리밍 등 고성능을 요하거나 복잡연산이 필요한 부분은 제외 하였습니다.
위의 요건을 정리 하게되면 우리가 할 작업의 목록이 생성이 되는데요. 인프라적인 요건과 테스트를 위한 Application생성 요건이되겠네요. 목록을 정리하면 아래의 표와 같습니다.
인프라적 요건
| 요건 | 내용 | 비고 |
| 사용자 생성 및 접근 권한 제한 | 사용자 별 쿠버네티스 접근권한 생성 | Service Account |
| 모니터링 구축 | Kubernetes Monitoring 구축 | Prometheus / Grafana |
| Kubernetes 백업과 복원 | Kubernetes 백업 구축 | velero |
| Kubernetes Log 확인 | Kubernetes Log System 구축 | EFK |
| Application Log 확인 | Application Log System 구축 | EFK |
| Application 배포 | Repository, CI/CD 구축 | Tekton / gitea / argo-cd |
| Application 수평 확장 / 축소 | HPA 구성 | Applicaion HPA |
| Web page 외부 노출 | Node port 생성 | Service |
| Domain 분기 사용 | Ingress 사용하여 Domain 분기 생성 | Ingress |
| 날씨 정보 수집 | batch 생성 | batch |
| Log In 가능 | Applicaion Deployment 생성 | Deployment |
| 계정 정보, 날씨정보, 배포정보 수집 | DB Statemnt 생성 | Statefulset |
테스트를 위한 Application 요건
| 요건 | 내용 | 비고 |
| Log In 가능 | Log In Page 생성 | |
| Log In 정보를 DB에 저장 | DB 생성 | Log In 정보 Table 생성 |
| 배포 횟수를 표시해야 한다. | DB 생성 | 배포 횟수 정보 Table 생성 |
| 배포 횟수를 표시해야 한다. | DB 정보를 표시하는 메인페이지 생성 | 배포 횟수 정보 |
| 날씨 정보를 표시해야 한다. | DB 생성 | 날씨 정보 Table 생성 |
| 날씨 정보를 표시해야 한다. | DB 정보를 표시하는 메인페이지 생성 | 날씨 정보 |
위의 요건을 바탕으로 운영 시스템을 구축 해 보도록 하겠습니다. 우선 설치를 해야 하는 부분을 종합해야 하는데요. 위의 시스템적인 요건을 바탕으로 볼경우, 다행히 많은 부분이 기본 Kubernetes기능이고 모니터링, CICD, 백업, EFK의 Add-on이 설치 되어야 겠네요. Add-on을 구축해보도록 하겠습니다.
운영 환경 구성도



Node Spec
Node의 구성은 구성 할 수있는 최소의 성능으로 구축을 해보겠습니다. Playce Kube의 기본구성은 설치를 위한 Deploy, Control-Plane, Worker, Infra Node로 구성됩니다. Infra Node는 Worker의 한 종류로 일반 Pod는 배정되지 않고 Ingress와 CI/CD, Monitoring 등의 공용 인프라 서비스로 사용 됩니다.
모든 Node는 물리적 장애를 대비하여 2기 이상 구성되지만, Kubernetes의 구축과 Bastion서버로 이용될 Deploy는 이중화 구성에서 제외 됩니다.
OS는 Ubuntu 22.04를 사용하고, 각 Node는 최소 4Core, 8GB Ram, 100GB Disk 이상을 필요로 합니다.
이 때 Deploy는 Repository구성을 위해 1TB 정도의 Disk 가 필요 합니다.
이미지를 통해 자세히 보겠습니다.

Shared Storage
NFS는 NAS혹은 nfs-server 기능을 이용해 사용 하도록 하겠습니다. Playce Kube는 테스트용 NFS를 구축해서 제공하지만, 단순 테스트용으로 성능 및 안정성을 위해서 별도 장비를 이용하는 것 이 좋습니다.
이미지를 통해 자세히 보겠습니다.

Application Architecture
Add-on을 구축 하기 전 간단한 테스트용 구성입니다. WEB - WAS - DB 3tier의 구성으로 구축을 하고, 성능에따라 수평 확장을 구성해 보겠습니다.
어플리케이션을 구축한다면 당연하게도 이 어플리케이션이 정상적으로 동작 하고 있는지를 확인 할 수 있어야 하고, 확인 하는 방법까지 고려되어야 하겠습니다. 이 방법을 통해서 차후에 모니터링의 기초를 다질수도 있겠습니다.
이미지를 통해 자세히 보겠습니다.
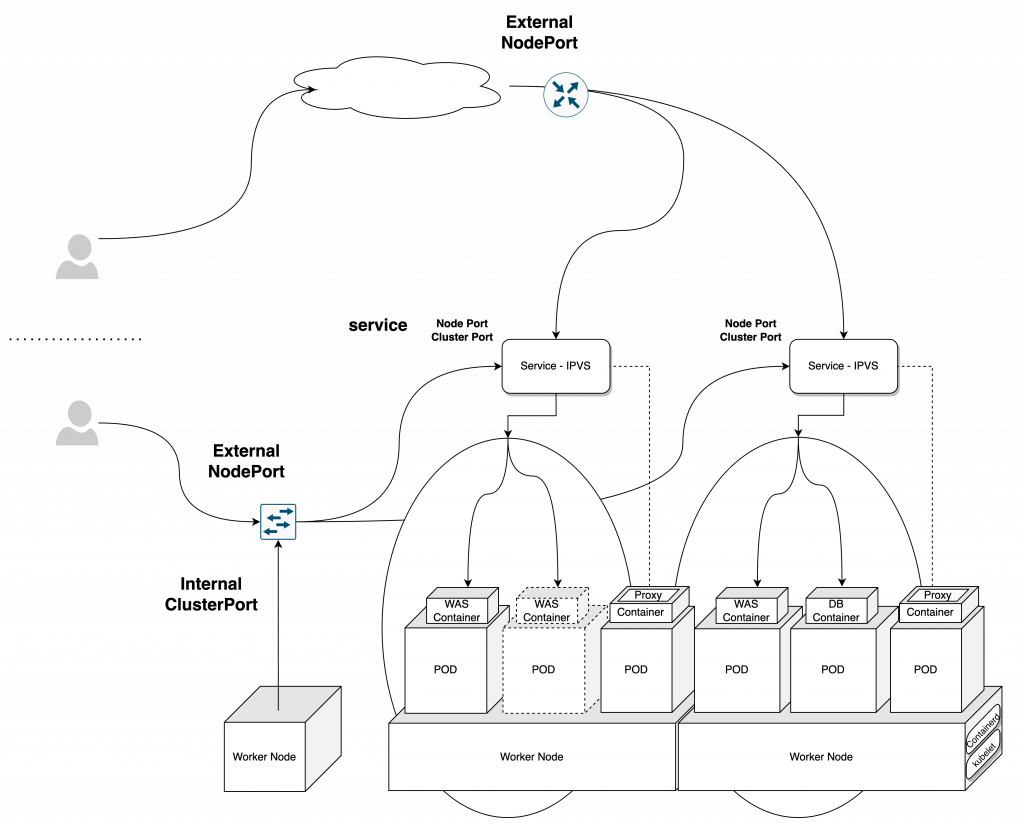
Kubernetes를 운영하기 위해서는 최소 사양과 권장 사양등을 설계시에 구분 할 필요가 있습니다. 그러기 위해서는 설계단계에서 서비스가 사용할 어플리케이션의 성능( 사용자 수, 사용자별 사용성능, 어플리케이션의 복잡도등 )을 고려해야 하고, 서비스가 사용하게 될 Add-on( EFK, Logging, Monitoring, CICD, Registry )의 선택과 성능을 예측해야 합니다.
시간에 지남에 따라 사용자의 증가와 추가 어플리케이션등의 확장도 고려해야 하겠죠?
물론 운영을 위한 Management 네트워크와 내/외부를 구분하는 네트워크, NAS 네트워크와 Backup 네트워크또한 고려해야 합니다.
그렇다면 자동 수평확장이 가능한 Kubernetes는 구축 할때 고려해야 할 부분을 하나씩 살펴보면서, Kubernetes의 구축을 준비해 보겠습니다.
서버( Node ) 성능 구분
Kubernetes는 사용량에 따라 수평확장이 가능한 구조입니다. 수백 수천대를 수평확장 할 수 있죠. 그리고 확장된 환경 내에서 각 Pod들은 사용 성능에 따라서 자원을 분배하여 최적/최대의 사용을 이끌어 냅니다. 그러나 사용 할 수 있는 총 연산량은 확장된 물리 서버의 최대 연산량이상은 사용 할 수는 없습니다.
단순히 1기의 컴퓨터에서 볼때, 내가 사용할 만큼의 성능을 예측해서 최초 구매하여 사용 할 수 있지만 시간이 지나감에 따라 사용하는 프로그램이 늘고 연산량이 늘게 되면, 하드웨어적 조치를 취하기 전까지는 프로그램이 실행이 안되거나 지연 되는 현상을 볼 수 있습니다.
왜냐하면, 물리서버의 성능의 한계에서는 벗어 날 수 없기 때문 인데요. 준비된 서버가 1 Core, 1 GByte RAM, 1GByte Storage라면 서버의 처리능력과 저장능력은 지정된 성능 이내에서 한계가 정해져있기 때문입니다. 내가 아무리 좋은 프로그램을 개발하더라도, 한계가 확정된 서버에서는 1Core의 연산능력과 1GByte의 연산량, 그리고 1GByte밖에 저장할 수 밖에 없습니다.
Kubernetes 또한 동일합니다. Container Image가 아무리 작게 구성되어 있고, 분산 처리가 잘 된다고 해도, 필요로 하는 연산량이 더 많다면 처리가 느려지거나 과다 자원 사용으로 System Kill이 발생하거나 심하면 서버가 재부팅 되게 됩니다.
블럭을 이용한 성능 계획
그렇다면 우리는 성능의 사용 구분을 어떻게 하면 편하게 볼 수 있을까요?
Kubernetes는 Container를 쌓아서 구축하는 모습으로 많이 표현하는데요. 그렇다면 이것을 응용하면 우린 조금 더 편하게 성능 부분을 계산 할 수 있을 것으로 보입니다.
( 성능의 수직 확장이 가능하지만, Limit로 계획한 수치입니다. )
예를 들자면 Kubernetes의 컨셉처럼 배를 서버, 성능을 컨테이너로 생각하면 됩니다. 아래 그림을 보겠습니다.
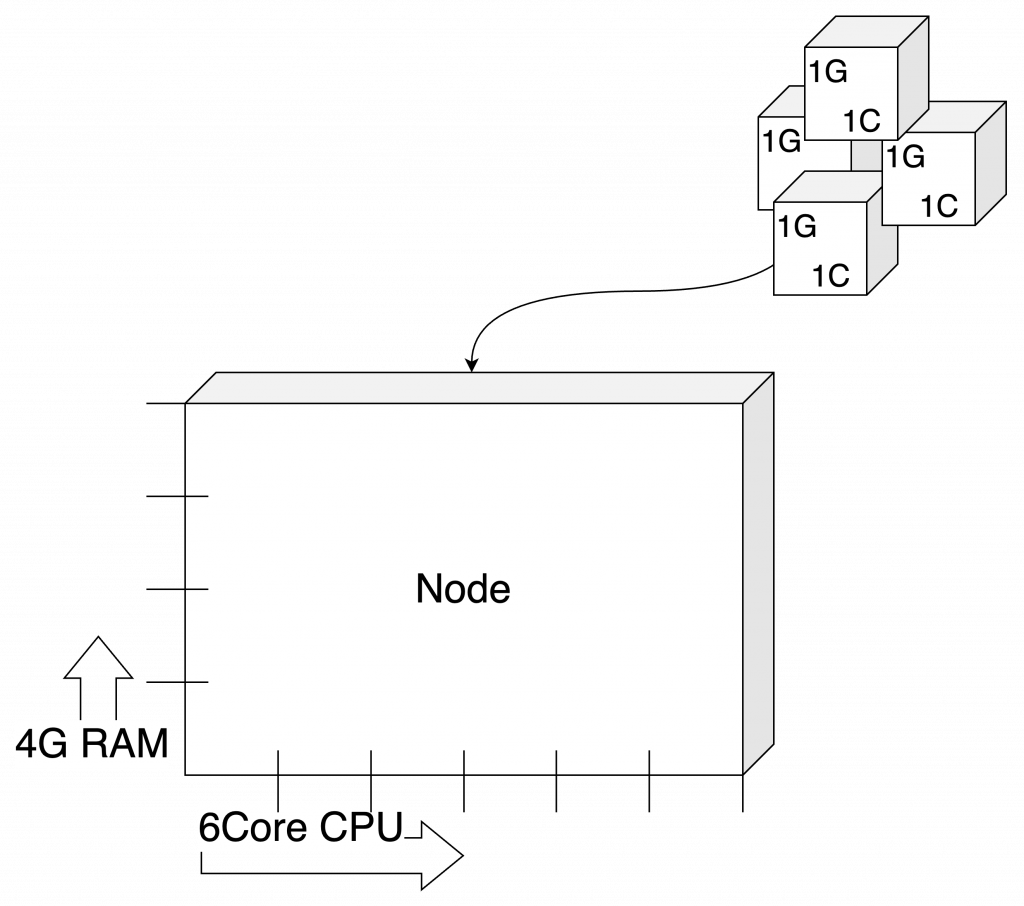
위 이미지에서 Node는 배이고 총 6Core, 4GByte의 RAM을 적재 할 수 있네요. ( 이 때, OS의 영역을 제외한 성능치여야 합니다. ) 정확히 1Core 1GByte RAM의 자원이 필요한 4개의 Container를 배치 하려는 이미지인데요.
Node안에 배치해보겠습니다.

아쉽게도 RAM의 한계로 인해 4개의 Container가 동시 운영된다면, Node의 성능을 모두 사용하게 됩니다. CPU의 성능은 아직 여유가 있지만, RAM의 성능이 부족하게 되네요. 하지만 블럭을 쌓아야 하는데 빈 공간이 너무 보입니다.
그렇다면, 순차적으로 사용한다면 어떤 배치가 가능할까요? 아래의 그림을 보겠습니다.

블럭 쌓기라면 위의 그림 처럼은 되지 않을까요?
좌측의 그림처럼 되려면, CPU를 순차적으로 호출 한다면, 가능할 것으로 보입니다.
우측의 그림은 같은 메모리를 반환 하면서, 순서를 기다려서 여러번 처리 한다면 가능해 보입니다.
하지만 우리의 시스템은 두 이미지 처럼 사용 되기를 바라지만 동시 다발적으로 동시에 연산이 이루어지는 우리의 System은 그렇지 못합니다.
우선 좌측의 이미지를 보면, 동일 Core는 4번의 동일 처리가 되지 않습니다. ( 물론 처리가 빠른경우 1사이클이 종료되기 전에 메모리만 점유하여 처리가 되지만, 연산이 동시에 이루어진다면 불가능한 연산입니다. )
이어서 우측의 이미지를 본다면, Container는 지속적으로 메모리를 반환하고 있어야 합니다.
그렇다면, 어떻게 해야 성능의 최대 사용량을 확인 할 수 있을까요? 생각보다 간단합니다.
모든 블럭들을 공유하지 않는다고 생각하고 대각선으로 블럭을 올려보고, 최대 요청량을 확인한다음, 사용량 예측에 따라서 공유될 자원의 요율을 조정 하면 되겠습니다.
그럼 Node를 어떻게 구성할지 노드 크기에 대한 고민을 이어서 해보겠습니다.
Container는 계획에 따라 크게도 작게도 만들 수 있습니다. 위의 계산처럼 단순히 1Core 1GByte RAM이라면 좋을 수 있지만, 그럴 수는 없을 것입니다.
단순히 구분을 한다면 웹처리의 경우 Core는 작게 RAM은 조금 크게 계획 할 수 있고, 연산처리의 경우 Core와 RAM모두 크게 계획하고, 메모리 캐쉬의 경우에는 Core는 작게 RAM은 크게 계산하면 되겠습니다. Batch의 경우에는 CPU를 크게 사용하는 계획하면 되겠습니다.
- Big Core, Small RAM
- Small Core, Big RAM
- Big Core, Big RAM
- Big Core, Big RAM
우선 이렇게 네 가지로 블럭의 크기가 계획되겠네요. 계획한 블럭을 크기별로 구분해 최대 요청량에 대한 성능을 보겠습니다.

이미지로 보게 된다면, 듬성 듬성해보이지만, 내가 원하는 최대치를 계산할때 필요한 이미지입니다. Pod또한 최소 2개를 구성 할때의 최대 성능까지 보았는데요. 과연 이 많은 Container들이 동시에 운영될까요?
만약 그렇다면 우리는 과감히 Kubernetes운영을 포기해야 합니다.
성능이 확정된 서비스는 Kubernetes를 운영하는 것이 비 효율적이기 때문인데요. 확정이 아닌 Container들이 시간차 혹은 로직에 따라 예상되는 숫자를 감안하여 사용이 된다면, 어떤 모습이 될까요?

혹시 느껴지실지 모르겠지만 성능의 많은 확보가 되었네요.
( *주의: 권장하거나 레퍼런스는 아닙니다. 이해 하기 쉽게 배분한 이미지 입니다. 성능의 구분과 요율에 따라 달라질 수 있습니다. )
설명을 해보자면, 각 각 2개의 Container구성에서 Big Core는 CPU 부분을 사용할 것을 대비하여 Core사용을 100%, RAM 을 50% 요율 계산하였고, Big RAM의 경우에는 Core사용을 50%, RAM을 100% 요율 계산하였습니다.
* { (2Core), (1GByte RAM) } X 2 => { (2Core X 1), (1GByte RAM X 0.5) } X2
이 때 Big CPU, RAM의 경우에는 100% 사용을 예상하고 계산하였습니다만 실제로는 80% 정도 계산하면 되겠죠. Small Coer, RAM은 50% 사용으로 계산 하였습니다.
그렇다면 왜 이렇게 계산을 했을까요?
CPU 혹은 RAM을 단일로 크게 사용하는 경우, 3개 이상의 Container가 사용된다면, 사용 후 제거가 되면서 한번에 많은 자원이 즉시 반납 되면서 공간의 여유가 크게 생기게 되어 자원의 효율이 떨어지게 됩니다만 반대로 확장될 경우, 자원의 사용이 폭증하게 되므로 자원의 여유가 많이 필요 하게 됩니다.
급작스런 변화에 대비라고 보시면 되겠습니다.
그리고, CPU와 RAM을 대량으로 사용하게 되는 Container의 경우 특히 조심해야 합니다.
자원의 여유가 없다면, 생성이 되지 않을 뿐더러 Node의 장애발생 시, 생성 공간의 부족으로 인해 장애로 이어 질 수 있습니다.
그러나 예상 성능이 작은 Container의 경우, 그 수량이 많지 않다면, 최소한으로 구성해도 좋습니다. 성능의 여분 자리에서 충분히 구성 될 수 있기 때문입니다.
위의 방법은 성능을 예측하기 위한 방법이기에 모든 어플리케이션에 적용되는 방법은 아닙니다.
하지만, 서로 대비되어 더 많이 사용되는 부분을 기준으로 Node 사용을 기준 잡아 설명 해 보았습니다.
모두 동의 하실지는 모르겠습니다만, 적어도 제가 보기에는 괜찮은 방법으로 제시드릴 것 같습니다.
Container 크기에 따른 Node 크기 계획
위에서 구분한 Container 크기별 구분에서 볼때, 어떠한 크기의 Container라도 모든 Node에 적용이 가능할까요? 혹은 무조건 많은 CPU Core와 많은 RAM이 노드에 구성된다면 크거나 작은 Container를 다 수용 할 수 있는 것일까요?
잘 아시겠지만 그렇지는 않습니다.
1기의 커다란 Node에서 최대한 많은 Container를 운영한다면, 물리 서버의 장애에 대응하기 힘들고, Container의 추적이 쉽지 않게 됩니다. 그리고 가장 큰 이유는 Kubernetes에서 생성되는 Pod의 숫자가 110개( 초기설정, 변경가능 )이기 때문입니다.
운영 가능한 Pod의 숫자는 성능에 따라 변경이 가능하지만, 시스템 Pod등을 고려할때 천천히 늘리면서 테스트하기를 권장하고 IP Address의 할당(24bit)과 관계가 있으니 노드당 200개 미만으로 사용하시는 것을 권장드립니다.

다시 이어서 위 그림을 보겠습니다. Big Size 2기 혹은 Small Size 8기의 노드로 두 그룹의 그룹별 합산 성능은 동일 합니다.
하지만 Big Size Node에는 작은 Container를 최대치로 배치하게되면 서버의 관리는 쉽지만 Container의 관리가 어렵고 각 Container의 사용에 따라 Node의 성능의 낭비가 예상 됩니다.
반대로 Small Size Node에는 요구 성능이 큰 Container는 기동조차 되지 않습니다.
그렇다면 Container의 크기는 Node별 어느정도 크기여야 할까요?
노드별 어느정도의 Container의 크기는 너무 크게 계획하지 않겠지만, 최소한 Node크기의 1/10이하로 계획하셔야 합니다. 수량도 수량이지만, 장애 혹은 Container의 급격한 수량 변화를 예측한다면 1/10도 과하지 않다고 생각하게 될 것 입니다.
Kubernetes를 설계할 때, Node의 성능과 Container의 크기는 중요한 포인트가 될 것입니다.
반대로 필요한 성능과 수량을 잘 계산해서 사용한다면, 최적의 사용을 보여줄 것 입니다.
성능 계산 예제
그렇다면, Container별 사용량에 따라 필요한 Node를 구분 해 보겠습니다.
예상되는 최대치 성능으로 계산을 해보겠습니다.
예시로 두종류의 컨테이너를 구축 할 예정이며, 각 각 최대 4개, 8개의 Container가 운영 될 예정입니다.
이때, 서버는 물리 장애에 대한 대비가 되어야 하고, 3년간 매해 10%의 서비스 사용량 증가를 예상합니다. 이때 서버의 사용률은 성능의 40% 이하 였으면 합니다. 소수점 계산은 올림으로 계산하되, OS 부분은 제외하고 계산합니다.
Container 성능 계산: 1C 2G X 4 + 2C 4G X 8 == 20C 40G
요율 적용 ( 매 해 10%의 사용량 증가, 3년 사용, 물리 서버의 장애 대응, 3년후 평균 사용량 40% 의 성능 사용 가정, 소수점 올림, OS 미포함 )
요율 계산:
- 3년 후, 사용 성능 계산: 20C 40G X 1.1 X 1.1 X 1.1 == 27C 54G
- 평균 사용량 40%이하 계산: 27C 54G : X = 4 : 10
- 요구되는 필요 성능 == 67C 135G
구축 필요 서버 성능 67Core 135G Byte RAM 입니다. 이때 필요 Node는 Container 크기에 비례하여 계산합니다.
Container는 1C 2G, 2C 4G 이고, 1개 서버당 110개의 40% 이하로 보면 되겠습니다.
그리고 물리 장애를 대비하여, 최소 2기 이상의 Node구성이 필요합니다.
4개 Node 구성 시 성능:
- 67C / 4 == 17C 이상
135G / 4 == 34G 이상
2개 Node 구성 시 성능:
- 67C / 2 == 34C 이상
135G / 2 == 68G 이상
3년후, 운영되는 Container의 성능 예측 으로는 27C 54G 입니다. ( Node 성능이 아닌 요구 성능입니다. )
따라서, 서버 4기 Node구성 시, 27C / 4 == 6, Node 당 약 6개의 Core 가 운영될 것으로 보입니다.
서버 2기 Node구성 시, 27C / 2 == 13, Node당 약 13개의 Core가 운영될 것으로 보입니다.
이때 추가로 고려해야 할, 최대 생성 Pod 갯수도 110개는 한참 미달 할 것으로 보입니다.
두 가지 서버 구성안 모두 구성이 가능 할 것으로 보이고, 이때는 서버의 숫자가 적은 편을 택하여, 관리 포인트를 여서 Node 2기 구성안을 선택하시면 되겠습니다.
네트워크 성능 구분
네트워크는 Kubernetes를 구성할때 크게 1개 라인으로도 가능합니다. 하지만 보안과 서비스 사용의 구분을 고려하여 구성 해야 합니다.
우선 Kubernetes가 사용 할 Internal Line, 외부 서비스와의 접점으로 사용 할 External Line, NAS를 사용하기 위한 Data Line, 내부에서 접속 관리를 위한 Management Line 등으로 나눌 수 있겠습니다.
1개 라인으로 충분하다고 했지만 왜 이렇게 많은 회선을 고려해야 할까요? 그리고 각 네트워크 라인은 어떻게 구성해야 할까요? 아래 그림을 통해 보겠습니다.

우리가 IDC에서 혹은 Archtecture에서 흔히 보게 되는 System 구성도입니다.
구성해야 하는 네트워크를 가장 쉽게 볼 수 있는 이미지인데요. 익숙 하면서도 매번 새로운 이미지로 보입니다.
네트워크 성격에 따른 계획
위 에서 설명한 대로 크게 네 부분으로 볼 수 있습니다.
- External Line
- Internal Line
- Data Line
- Management Line
External Line은 외부에서 우리 서비스에 접근할때 사용하는 Line입니다.
주로 L4를 통해서 Worker의 Ingress 혹은 Service ( Node Port )로 접근 할 수 있게 합니다. 그리고 외부와 연동되어 있어 Pod에서 외부 기관등과 연동을 할때도 사용됩니다.
외부와의 통신에 이용되므로 사용량은 제공되는 서비스에 따라 구분됩니다.
매우 중요한 Line으로 서버 본딩과 네트워크 이중화를 통해 사용되며, 트래픽량은 유저수와 제공되는 서비스에 따라 트래픽량이 변경 됩니다.
( Ex: 웹 페이지를 제공시, 웹 페이지 X 예상 유저 수 X 보정치 == 트래픽 량 )
Internal Line은 Kubernetes의 API 통신과 Pod들의 통신에 사용됩니다. ( Playce Kube로 설치 시, 해당 네트워크를 이용해 API 통신이 이루어 집니다. ) 또한 물리 서버( Ex: DB, 혹은 인증 서버 등 )와의 연동으로도 사용합니다.
매우 중요한 Line으로 본딩과 네트워크 이중화를 통해 사용되며, 트래픽량은 유저 별 사용되는 시나리오에 따라 트래픽량이 변경 됩니다.
( Ex: Pod간 연동 시, { 시나리오별 내부 처리 데이터 X 예상 처리 수 X 시나리오 가중치 } X 보정치 == 트래픽 량 )
Data Line은 NAS 혹은 서비스 백업등에 활용됩니다.
매우 중요한 Line으로 본딩과 네트워크 이중화를 통해 사용되며, 트래픽량은 Pod에서 사용되는 데이터의 크기에 따라 트래픽량이 변경 됩니다.
( Ex: NAS 사용 시, [{ 데이터 크기 X 읽기 빈도 수 } + { 데이터 크기 X 쓰기 빈도 수 }] X 보정치 == 트래픽 량 )
Management Line은 콘솔 및 Node 관리용으로 API 명령 전달과 Monitoring 등에서 사용됩니다.
운영 혹은 관리자의 네트워크와 연동되며, 이중화가 되어 있지 않아도 되지만 네트워크 장애에 따른 대비책은 필요하고, API 통신만 사용되므로 최소한의 네트워크 성능이 보장 되면 됩니다.
( Ex: Management 사용 시, 최소 100M이상, 1G 이상 권장 )
다양한 Line이 있지만, 이중 사용 방법과 운영 방법에 따라 변경이 가능합니다.
예를 들자면, IDC내에 보안이 이미 되어 있어 External과 Internal회선을 분리 할 필요가 없을 경우 통합할 수 있습니다.
그리고, Internal Line과 Data Line을 합쳐서 하나의 Line으로 운영해도 되는 등 다양하게 운영될 수 있으므로 Kubernetes의 구축시, 제공 가능한 인프라 환경에 맞추어 구축이 가능합니다.
IDC내 연동( 인증, CICD, Loggin 등 )같은 별도의 Line이 있을 수 있지만 Internal 혹은 Data Line의 연장으로 봤을 때, 아래와 같은 회선이 필요하겠습니다.
- Exteranl + Internal + Data + Management == Total 1 Line
- Exteranl, Internal + Data + Management == Total 2 Line
- Exteranl + Internal + Data, Management == Total 2 Line
- Exteranl, Internal + Data, Management == Total 3 Line
- Exteranl, Internal, Data + Management == Total 3 Line
- Exteranl, Data, Internal + Management == Total 3 Line
- Exteranl, Internal, Data, Management == Total 4 Line
- ...
이 중, 가장 복잡한 네트워크 구성의 예시를 작성해 보겠습니다.

위의 설명과 같이 사용에 따라 나뉘어진 네트워크로 작성해 보았고, 필요에 따른 스위치 구성을 해보았습니다.
- 외부와 연결이 되어 서비스를 받을 수 있는 External Line
( 외부 서비스 사용을 위해 Default Route를 여기에 지정했습니다. )
스위치도 외부에서 접근을 보장하기 위해 별도 구성을 상정하였습니다.
DMZ등의 접속 구역 구분을 위해서도 별도 사용을 표시했습니다. - Kubernetes API와 Pod 네트워크를 위한 Internal Line
Pod간의 통신( kubectl과 Pod 네트워크를 담당합니다. ) - Data Line
iSCSI혹은 NAS를 이용한 Pod에서 사용하게 될 SC, PV의 접속을 지원합니다. - Manage Line / IPMI Line
IPMI는 물리 서버의 관리를 위한 LIne입니다.
Manage Line 은 보안을 대비한 내부 관리자용 접속 혹은 모니터링 라인이라고 보면 되겠습니다.
스위치는 외부와 내부를 크게 구분 했으며, 내부의 스위치는 대규모 트래픽을 예상해서 지금처럼 Line을 많이 구분 할 때는 백본 스위치가 구성되므로 1개의 스위치에서 VLAN을 이용하여 Line이 서로 침범 하지 않도록 합니다.
네트워크는 Kubernetes를 구성하고 사용 할때 버틀넥이 생기는 장애 포인트입니다.
서비스 제공 성능을 정하는 만큼 아주 중요한 포인트라고 볼 수 있는데요. 최대한 여유있게 잡아주시는게 포인트라고 볼 수 있습니다.
또한 쿠버네티스는 대규모 서비스를 대비한 시스템인 만큼 확장에도 신경을 써야 하는데요.
서버가 총 10기라면 본딩 및 서비스 구분에 따라 스위치당 회선 별 최소 15Port 사용이 가능한 스위치를 미리 구성하여 확장을 대비해야 합니다.( 개본 10개 Port + Up Link 1 ~ 2 + etherchannel 1 ~ 2 + 예비 1 ~ N ) Kubernetes는 사용이 자유로운 만큼 많은 서비스들이 생성되고, 이에 따라 서버의 수평 확장으로 Node가 증설 되므로 최소한의 고려사항은 아니더라도 고려사항으로 포함시켜 Node증설에 대비 할 수 있도록 하시면 좋겠습니다.
스토리지 성능 구분
스토리지는 Kubernetes의 기능에 핵심이라고 볼 수 있는데요.
단순히 데이터를 공유스토리지에 적재 하는 것이 아닌 이미지를 사용 할 때, 변동이 되는 부분과 변동이 되지 않는 부분을 나누고 모든 Node에서 접근 할 수 있는 상황을 제공해서 Pod 혹은 Container가 재기동 되었을때, 운영자가 원하는 상황으로 복구가 되는 핵심적인 요소라고 볼 수 있습니다.
물론 스토리지는 용량이 크면 클수록 좋지만, Kubernetes의 Namespace 혹은 서비스 군별 구분하여, 사용 하게 될 양을 사전에 예측하여야 하겠습니다.

특히 스토리지의 경우 언제나 우리가 예측하지 못하는 상황에 모든 것을 적제하는 실수를 반복하게 되는데요.
서비스 시작시 10% 미만 1년간 20%, 2년간 50%, 3년간 70%를 사용 하겠다는 정확한 예측치를 수렴해 구성해야 하며, 70%부터는 증설을 준비하고 80%가 되었을때, 즉시 증설을 해야 겠습니다.
만약 이 시기를 놓칠 경우 장애 복구와 증설에 어려움이 있을 수 있으므로 빠른 준비가 필요합니다.
Data는 주로 어플리케이션의 사용에 따라 달라집니다.
대용량 파일을 사용하거나 스트리밍 서비스를 사용할 경우 별도의 스토리지를 구성하고, 작은 파일로 다량( 일 억개 이상 )일 경우에도 최대한 스토리지를 분산하여 구축하여야 합니다.
다만 스토리지는 심플하게 사용량을 ( 최대 사용자 수 X 유저당 Data 크기 X 보정치 ) 로 보고 계산 할 수 있어, 서비스 사용간에 사용될 용량을 최대한 구성 하면 되겠습니다.
결론
Kubernetes를 이미 구성하셨거나, 구축을 준비하고 있는 단계에서 고려하고 준비 해야할 Kubernetes의 구축 포인트를 살펴 봤습니다. 각 자의 인프라 환경과 보안 사항 그리고 어플리케이션등의 구조가 다를 수 있습니다만, 최소한의 Kubernetes를 설치 하고 운영하기 위한 고려사항을 정리 해봤습니다.
성능과 구조이기에 의견이 다르거나 최적의 구성을 하기에는 부족하다고 보실 수 있겠지만 큰 틀에서 고려사항들을 정리 해보았습니다.
물론 부족하지만, 서버와 네트워크, 그리고 스토리지 부분의 구축 포인트를 담고 있습니다만, 스토리지 부분은 조금 더 부족하다고 느끼실 수 있습니다.
스토리지는 어플리케이션에 따라 천차만별로 달라지고, 보관량에 따라 달라지므로 최대한 많이 확보를 해주시면 되겠습니다.
이제 Node의 성능과 네트워크의 정리, 그리고 Storage의 크기를 계산하였다면, Kubernetes를 구축 할 수있는 준비가 된 것 같습니다.
실제로 테스트 서버의 준비 혹은 실제 서버에서 Playce Kube를 구축하고, 사용하며 좀더 쉽고 안정적인 Kubernetes를 사용 하셨으면 좋겠습니다.
Kubernetes란 무엇인가를 시작으로, 고객의 니즈와 서비스 형태를 바탕으로 완성한 쿠버네티스 시스템을 분석하여 블로깅 하고 있습니다.
우리 모두 오픈소스컨설팅의 미션 처럼 기술을 나누고, 모두 함께 성장했으면 좋겠습니다.
# 어플리케이션 구조는 계속 업데이트 예정입니다.
갈길이 멀어 보이네요. 우리 힘냅시다.
'kubernetes' 카테고리의 다른 글
| Playce Kube - 설치 확인 (0) | 2023.05.13 |
|---|---|
| Playce Kube - 서버 준비 (0) | 2023.02.21 |
| Playce Kube - 설치 (0) | 2023.01.14 |
| Playce Kube - 구조 (0) | 2022.08.29 |
| Kubernetes 구조 (2) | 2021.03.03 |